集合
Guava对JDK的集合做了扩充,主要表现在:
- 增加了一些新的集合类
- 更好的不可变集合
- 增加了更多实用的集合处理方法
新增集合
MultiSet
记录集合中元素的重复次数。注意,这个类并不继承Set接口,而是直接继承Collection
MultiSet继承关系:
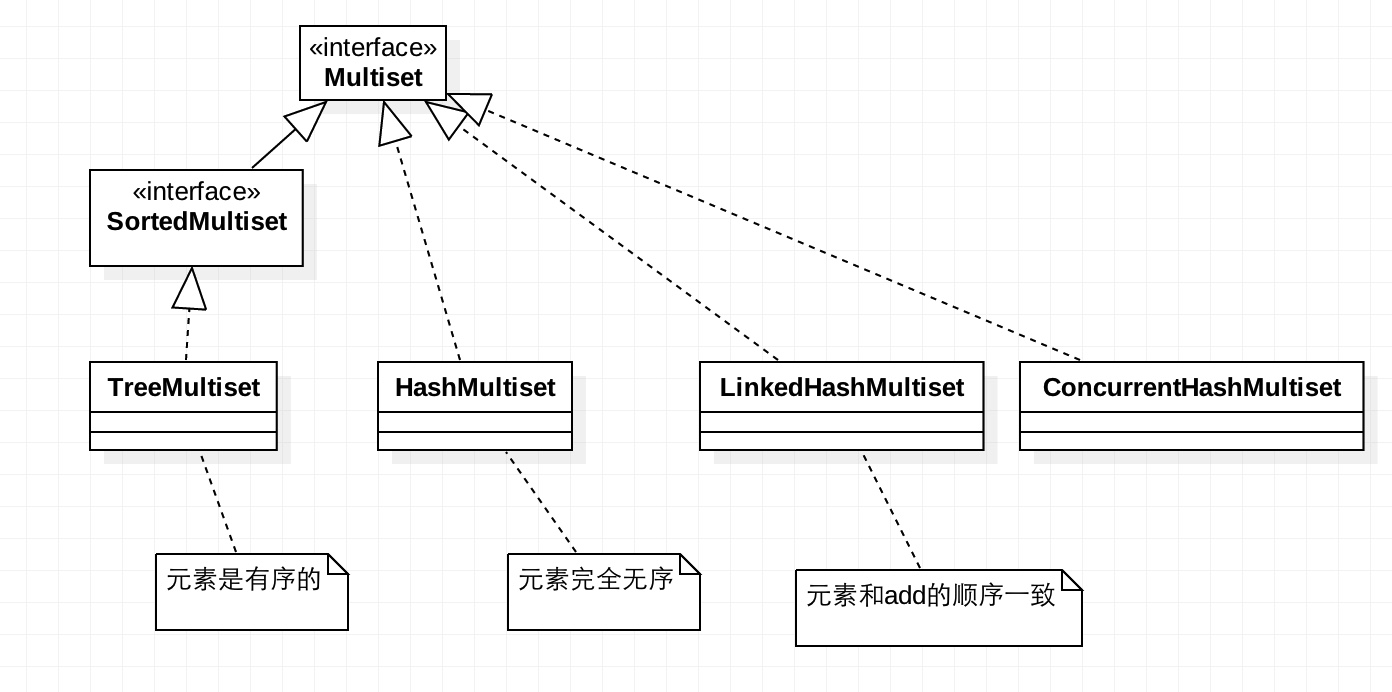
为啥要看下MultiSet的类图:
- 直观的看下类的继承结构
- 创建对象的时候,都是通过
subClass.create()方式创建的,不记得实现类就不知道咋创建啊。
@Test
public void test13() {
//treeMultiSet保证元素有序
SortedMultiset<String> multiset = TreeMultiset.create();
multiset.add("5", 3);
multiset.add("1");
multiset.add("2");
multiset.add("3");
multiset.add("1");
multiset.add("2");
System.out.println(multiset.elementSet());//不重复的 [1, 2, 3, 5] 自然成序
for (Multiset.Entry<String> entry : multiset.entrySet()) {
System.out.println(entry.getElement() + " count: " + entry.getCount());
}
//[2,5)直接的元素,组成的multiSet
System.out.println(multiset.subMultiset("2", BoundType.CLOSED, "5", BoundType.OPEN));
Multiset<String> hashMultiSet = HashMultiset.create();
hashMultiSet.add("5", 3);
hashMultiSet.add("2", 2);
hashMultiSet.add("3", 2);
System.out.println(hashMultiSet.elementSet());//[3, 2, 5] 既不自然成序,也和add的顺序不一致
Multiset<String> linkedHashMultiSet = LinkedHashMultiset.create();
linkedHashMultiSet.add("5", 3);
linkedHashMultiSet.add("2", 2);
linkedHashMultiSet.add("3", 2);
System.out.println(linkedHashMultiSet.elementSet());//[5, 2, 3] 和add的顺序一致
}
运行结果:
[1, 2, 3, 5]
1 count: 2
2 count: 2
3 count: 1
5 count: 3
[2 x 2, 3]
[2, 3, 5]
[5, 2, 3]
BiMap
BiMap继承于Map接口
功能:双向Map,既可通过key取value,也可通过value取key。
要求:key唯一,value唯一
实现类:HashBiMap
示例:
@Test(expected = IllegalArgumentException.class)
public void test1()
{
BiMap<Integer, String> map = HashBiMap.create();
map.put(1, "0");
map.put(2, "0");
map.put(1, "1");
System.out.println(map.toString());
System.out.println(map.inverse().toString());
System.out.println(map.toString());
}
@Test
public void test1() {
// 双向map---因为是双向的,key集合和value集合必须都是唯一的
BiMap<Integer, String> biMap = HashBiMap.create();
biMap.put(1, "hello");
biMap.put(2, "helloa");
biMap.put(3, "world");
biMap.put(4, "worldb");
biMap.put(5, "my");
biMap.put(6, "myc");
int value = biMap.inverse().get("my");
System.out.println("my --" + value);
System.out.println(biMap.inverse().inverse().get(2));
}
MultiMap
MultiMap并不继承于JDK的任何接口。
功能:一个key对应多个value的map,类似Map<Object,List>。添加元素时自动将key相同的元素放到List中
类图如下:
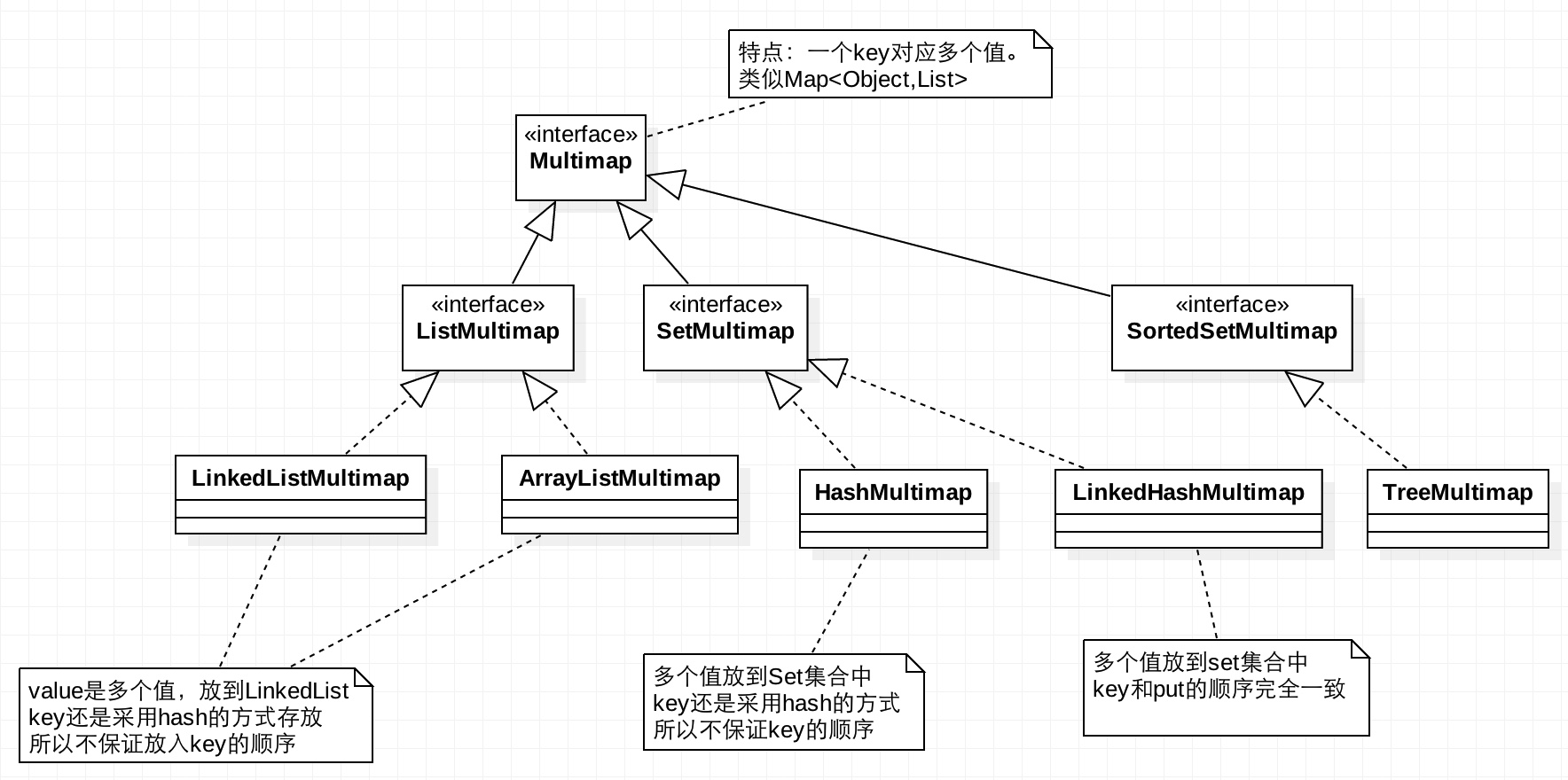
示例如下:
@Test
public void test14() {
ListMultimap<Integer, String> listMutilMap = ArrayListMultimap.create();
listMutilMap.put(100, "1001");
listMutilMap.put(2, "21");
listMutilMap.put(2, "22");
listMutilMap.put(1, "1");
listMutilMap.put(1, "2");
listMutilMap.put(43, "431");
System.out.println(listMutilMap.keySet());//key采用hash的方式,不保证key的顺序,value放到List中
Multimap<Integer, String> multiMap = LinkedHashMultimap.create();
multiMap.put(100, "1001");
multiMap.put(2, "21");
multiMap.put(2, "22");
multiMap.put(1, "1");
multiMap.put(1, "2");
multiMap.put(43, "431");
System.out.println(multiMap.keySet());//key和add的顺序一致
Multimap<Integer, String> hashMultimap = HashMultimap.create();
hashMultimap.put(100, "1001");
hashMultimap.put(2, "21");
hashMultimap.put(2, "22");
hashMultimap.put(1, "1");
hashMultimap.put(1, "2");
hashMultimap.put(43, "431");
System.out.println(hashMultimap.keySet());//key采用hash的方式,不保证顺序,value放到set中
SortedSetMultimap<Integer, String> sortedSetMultiMap = TreeMultimap.create();
sortedSetMultiMap.put(100, "1001");
sortedSetMultiMap.put(2, "21");
sortedSetMultiMap.put(2, "22");
sortedSetMultiMap.put(1, "1");
sortedSetMultiMap.put(1, "2");
sortedSetMultiMap.put(43, "431");
System.out.println(sortedSetMultiMap);//key保证有序(升序),相同的key的value也有序(升序)
}
输出:
[1, 2, 100, 43]
[100, 2, 1, 43]
[1, 2, 100, 43]
{1=[1, 2], 2=[21, 22], 43=[431], 100=[1001]}
[1, 2, 43, 100]
Table
Table不继承于JDK的任何接口。
功能:Map是通过一个key对应一个value,Table是通过两个key同时决定一个value。有点类似于联合索引,可以看成是
Map<row,Map<col,value>>
类图如下:
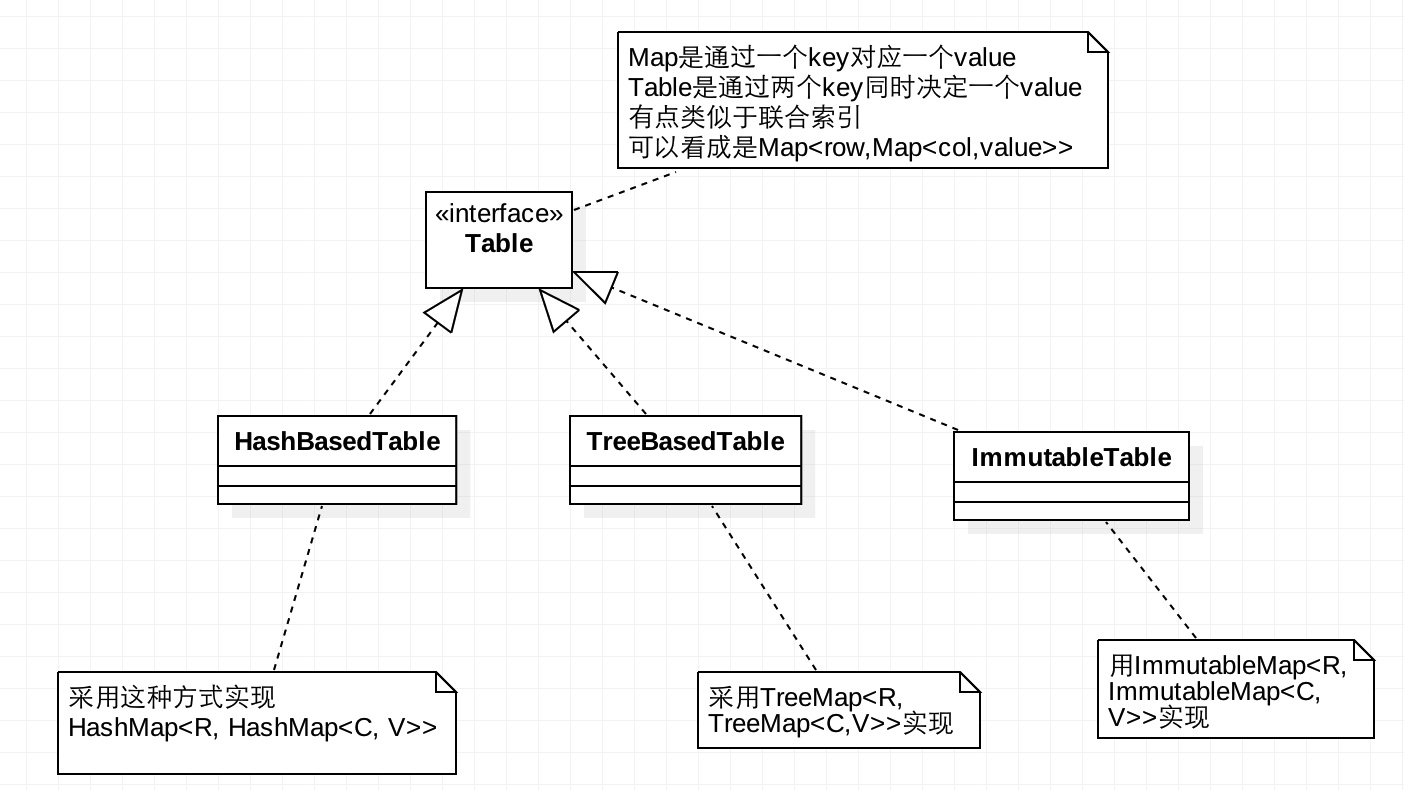
示例:待补充,很少用到这个类
RangeSet
功能:范围集合,结合Range类使用,能够自动合并相连区间。 实现类:TreeRangeSet 示例代码:
@Test
public void test16() {
RangeSet<Integer> rangeSet = TreeRangeSet.create();
rangeSet.add(Range.closed(1, 10)); // {[1,10]}
System.out.println(rangeSet);
rangeSet.add(Range.closedOpen(11, 15));//不相连区间:{[1,10], [11,15)}
System.out.println(rangeSet);
rangeSet.add(Range.closedOpen(15, 20)); //相连区间; {[1,10], [11,20)}
System.out.println(rangeSet);
rangeSet.add(Range.openClosed(0, 0)); //空区间; {[1,10], [11,20)}
System.out.println(rangeSet);
rangeSet.remove(Range.open(5, 10)); //分割[1, 10]; {[1,5], [10,10], [11,20)}
System.out.println(rangeSet);
}
结果如下:
[[1‥10]]
[[1‥10], [11‥15)]
[[1‥10], [11‥20)]
[[1‥10], [11‥20)]
[[1‥5], [10‥10], [11‥20)]
RangeMap
RangeMap不继承于JDK的任何接口。
功能:key在一个范围内,映射一个value。
实现类:TreeRangeMap
示例代码:
@Test
public void test18() {
RangeMap<Integer, String> rangeMap = TreeRangeMap.create();
rangeMap.put(Range.lessThan(60), "不及格");
rangeMap.put(Range.closedOpen(60, 70), "凑合");
rangeMap.put(Range.closedOpen(70, 80), "再接再厉");
rangeMap.put(Range.closedOpen(80, 90), "良好");
rangeMap.put(Range.closed(90, 100), "优秀");
System.out.println(rangeMap.get(68));
}
结果:
凑合
Guava集合类和JDK集合类的关系类图
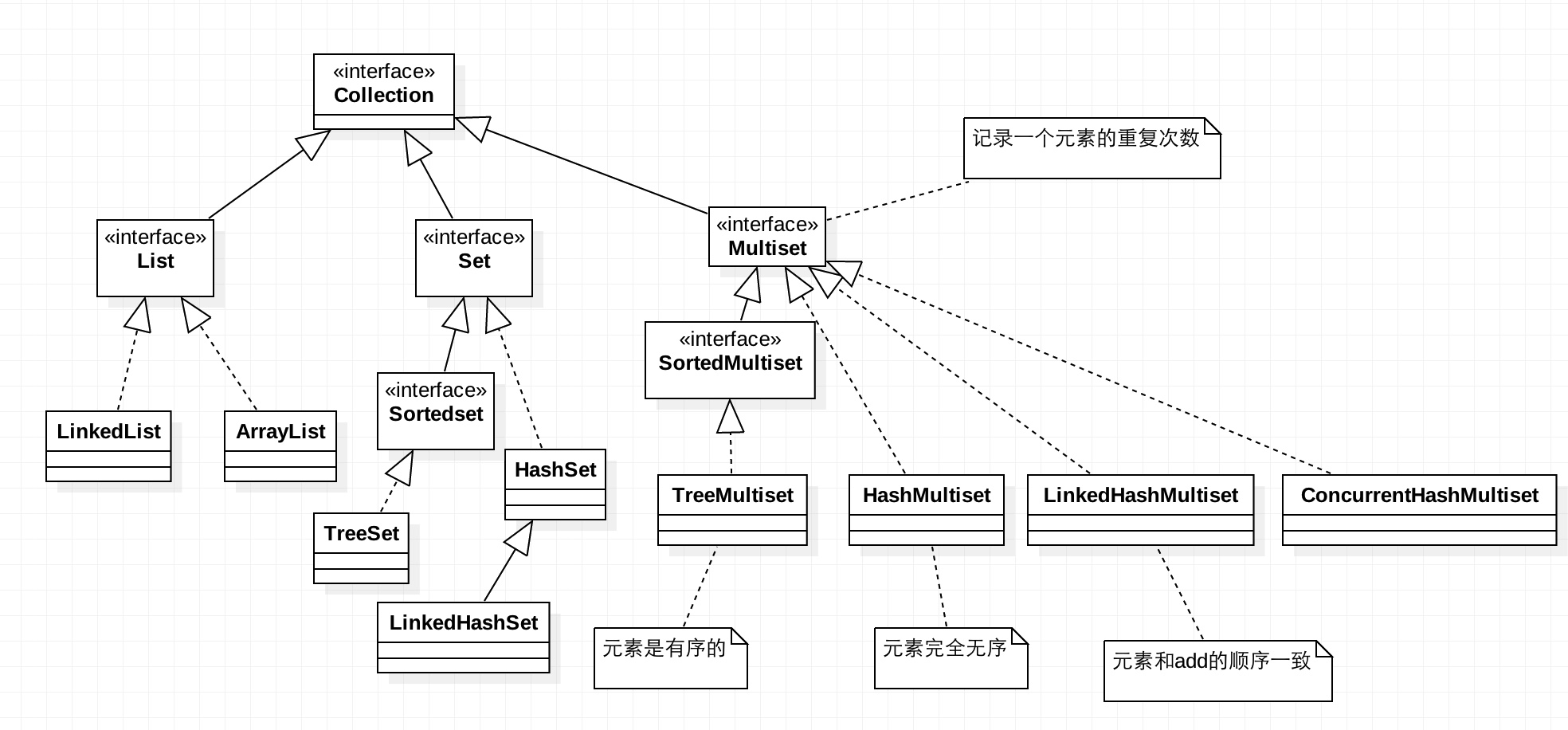
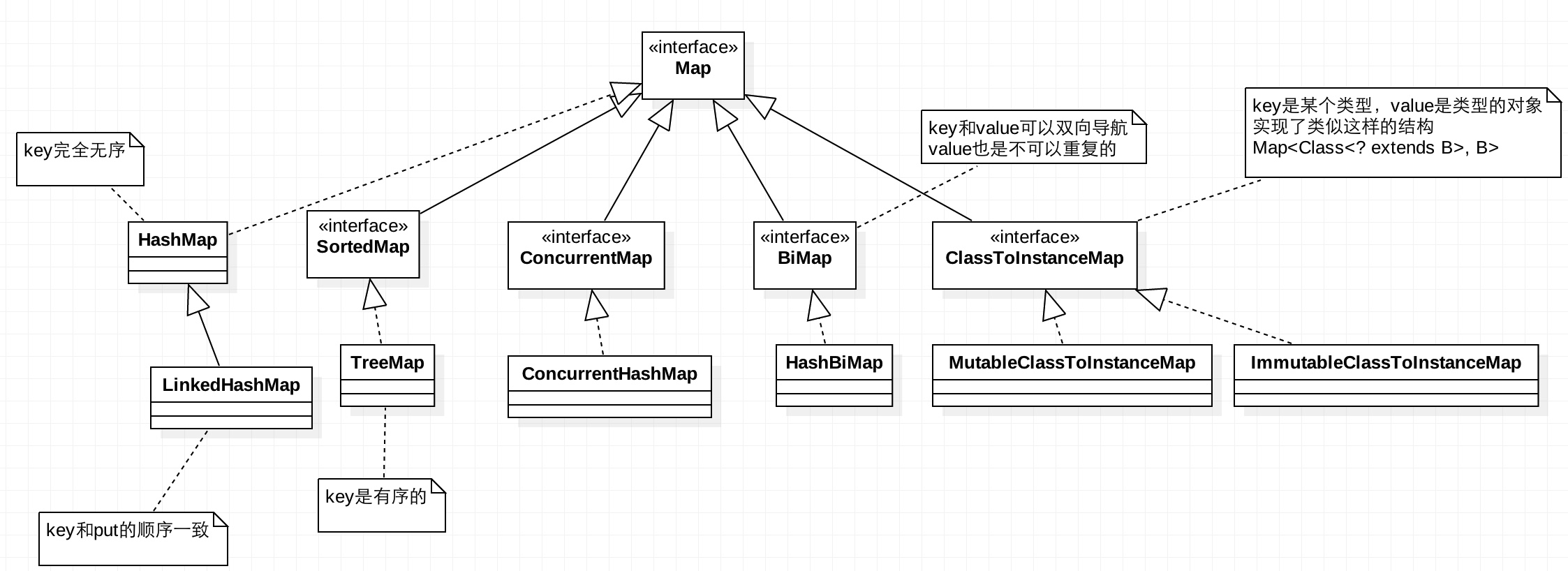
需要注意:
- MultiMap、RangeMap并不继承Map接口,也不继承Collection接口
- RangeSet并不继承Set接口,也不继承Collection接口
不可变集合
Guava不仅提供了上述集合类的不可变版本,也提供了JDK中的集合的不可变版本。对应如下:
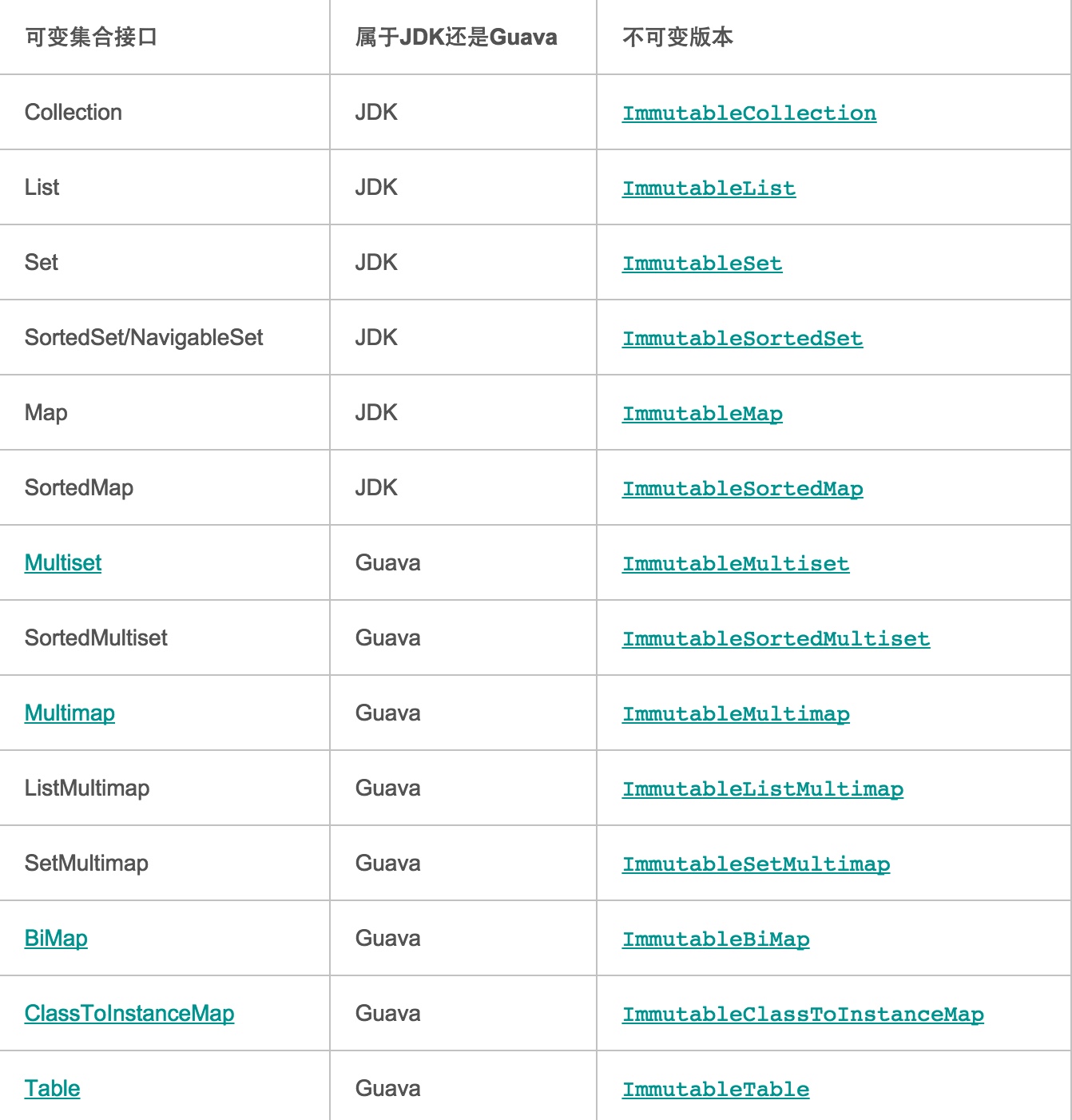
JDK提供的不可变集合示例:
@Test
public void test2()
{
List<String> list = Lists.newArrayList("a", "b", "c");
Collection<String> unmodifiableCollection = Collections.unmodifiableCollection(list);
// unmodifiableCollection.add("d");//exception..
list.add("e");//origin list can also add element and add to unmodifiableCollection
System.out.println(unmodifiableCollection);
}
输出:[a, b, c, e] JDK本身提供的集合类可以将一个list封装为它的不可变版本。但是原list仍可以添加数据,并对封装后的集合有影响。 Guava提供的不可变集合示例:
@Test
public void test3()
{
List<String> list = Lists.newArrayList("a", "b");
ImmutableList<String> immutableList = ImmutableList.copyOf(list);
list.add("c");// origin list add element can not affect immutableList
System.out.println(immutableList);
}
输出:[a, b] 其实是copy了一份,但是这个copy很智能。下面来源于官方文档:
作为一种探索,
ImmutableXXX.copyOf(ImmutableCollection)会试图对如下情况避免线性时间拷贝:
- 在常量时间内使用底层数据结构是可能的——例如,
ImmutableSet.copyOf(ImmutableList)就不能在常量时间内完成。- 不会造成内存泄露——例如,你有个很大的不可变集合
ImmutableList<String> hugeList,ImmutableList.copyOf(hugeList.subList(0, 10))就会显式地拷贝,以免不必要地持有hugeList的引用。- 不改变语义——所以
ImmutableSet.copyOf(myImmutableSortedSet)会显式地拷贝,因为和基于比较器的ImmutableSortedSet相比,ImmutableSet对hashCode()和equals有不同语义。 在可能的情况下避免线性拷贝,可以最大限度地减少防御性编程风格所带来的性能开销。
更多的集合处理方法
对集合的处理,目前我经常用到的有:
- 索引
- 去重
- 集合运算
对于其他的处理方法,以后用到慢慢补充。
索引
经常有这样的需求,比如有一个技师信息的List,现有一个TechnicianId,要在List中找出这个TechnicianId对应的技师信息。 原来我们可能会写类似这样的代码:
public TechnicianDTO findByTechnicianId(int technicianId) {
for (TechnicianDTO technicianDTO : technicianDTOs) {
if (technicianDTO.getTechnicianId() == technicianId) {
return technicianDTO;
}
}
return null;
}
这样的写法,每次查询technicianId都需要遍历一遍technicianDTOs,更聪明的做法,将technicianDTOs转换为一个Map<Integer,TechnicianDTO>,key为TechnicianId,value为对应的TechnicianDTO。
在Guava看来,完成这样的转换就相当于给一组TechnicianDTO数据的TechnicianId字段上加了索引,事实上也的确如此,所以Guava提供了方便的加索引方法,索引本身有两种:唯一索引和非唯一索引。上面这个列子中,根据业务含义,可以加唯一索引,如果加非唯一索引,返回的结果类似于Map<Integer,List<TechnicianDTO>>,相当于根据某个字段聚合了。分别看如下代码:
/**
* 对集合添加唯一索引
* @param technicianId
* @return
*/
public TechnicianDTO findByTechnicianId2(int technicianId) {
ImmutableMap<Integer, TechnicianDTO> uniqueIndex = FluentIterable.from(technicianDTOs).uniqueIndex(new Function<TechnicianDTO, Integer>() {
@Override
public Integer apply(TechnicianDTO technicianDTO) {
return technicianDTO.getTechnicianId();
}
});
return uniqueIndex.get(technicianId);
}
/**
* 对集合添加非唯一索引
* @param technicianId
* @return
*/
public List<TechnicianDTO> findByTechnicianId(int technicianId) {
ImmutableListMultimap<Integer, TechnicianDTO> index = FluentIterable.from(technicianDTOs).index(new Function<TechnicianDTO, Integer>() {
@Override
public Integer apply(TechnicianDTO technicianDTO) {
return technicianDTO.getTechnicianId();
}
});
return index.get(technicianId);
}
去重
展示了两种去重情况:1. 保证去重后和原始序一致 2. 不保证顺序
@Test
public void test50() {
List<Integer> list = Lists.newArrayList(1, 2, 2, 1, 4, 5, 4, 3);
ImmutableList<Integer> distinct = ImmutableSet.copyOf(list).asList();//保证序和原始序一致
HashSet<Integer> distinct1 = Sets.newHashSet(list);//不保证序和原始序一致
System.out.println(distinct);
System.out.println(distinct1);
}
集合运算
集合运算主要有:并集、交集、差集。
代码:
@Test
public void test51() {
List<Integer> list1 = Lists.newArrayList(1, 2, 2, 1, 4, 5, 4, 3);
List<Integer> list2 = Lists.newArrayList(1, 2, 3, 7, 8, 9);
Sets.SetView<Integer> union = Sets.union(Sets.newHashSet(list1), Sets.newHashSet(list2));
Sets.SetView<Integer> difference = Sets.difference(Sets.newHashSet(list1), Sets.newHashSet(list2));
Sets.SetView<Integer> intersection = Sets.intersection(Sets.newHashSet(list1), Sets.newHashSet(list2));
System.out.println(union);
System.out.println(difference);
System.out.println(intersection);
}
结果如下:
[1, 2, 3, 4, 5, 7, 8, 9]
[4, 5]
[1, 2, 3]